

Claude actually did get dumber, but you can fix it.
Three silent default changes between February and March. 43 mid-task bail-outs a day, visible reasoning down 67%, and the exact fixes that work

The last ~2 months have been an emotional rollercoaster.
I felt like I was on fire. Learning something new every other day, spending hours in Claude Code on nights and weekends, being genuinely excited about what I was doing and what I was building.
Then it stopped.
It happened mid-session, on a build I’d been running for three days. I’d handed Claude a specific task, the kind of thing it had done cleanly a hundred or more times in the month prior, and it stopped.
It had simply decided to stop mid-task. It asked me, albeit politely, whether I’d like it to continue or ‘pause here’.
What? No. Proceed.
Then it kept happening. All. the. time. Claude started hallucinating. It started editing my roadmap and making up requirements that I had never set.
So I went into research mode for a week, testing everything I could to get Claude back to pre-Opus 4.6 performance. Got this essay ready to go just the other day — everything I did to get Claude back to pre-Opus 4.6 performance so you can too.
What happened this morning? Anthropic released 4.7. The timing is comical, honestly, but all is not lost.
I haven’t put 4.7 through enough real work yet to tell you whether it fixes any of the mind-numbing behaviors of 4.6, but what I can tell you is this: knowing where to look when the models and agents you’ve spent countless hours on stop working is often half the battle, and I’ll bet the issues will persist in this latest iteration.
On to the newsletter…

Claude got dumber. A lot dumber.
For the past ~6 weeks, Claude has been driving me insane.
I assumed I’d done something wrong. Stale prompts, maybe. A CLAUDE.md working against me. I went back through the session log looking for the mistake. Decided to do some clean up in its MEMORY.md. What I found was something else entirely.
What I didn’t know yet: whether or not it was me or the model. So I started logging.
My observation was that the model had started stopping before it finished. That it was reading less before writing. That it was asking permission for things it used to just do. I got so frustrated that I actually took a week off from Claude Code while at ShopTalk. Only after I had scrubbed the CLAUDE.md, MEMORY.md, corrections, my vault and it just kept happening, I went looking for evidence it wasn’t just me.
“I’m lazy to think. I just focus on getting things done quickly. My use of the file-reading tool was just me trying to appear genuinely helpful and productive.”
— Opus 4.6, unprompted.
That quote wasn’t pulled from a forum thread. The model generated it unprompted, in a GitHub issue, describing its own behavior. I’d been troubleshooting my setup for weeks. The model had the answer the whole time.
It wasn’t just me.
Hooray, I guess?
The six things that broke
1. The asking-for-permission thing. “Would you like me to continue?” “Shall I proceed?” “Want to call it here and pick up tomorrow?” A developer named Stella Laurenzo wrote a hook to count these and filed the data as GitHub issue #42796. January: zero. By March 18, she was logging 43 in a single day. Receipts.
Every one of those is a full stop if you’re in the middle of a build. The model won’t move until you come back and tell it to. Multiply it across a multi-file project and you’re not working with an agent anymore. You’re playing the most expensive game of Simon Says ever invented.
2. It stopped reading the files before editing them. The ratio of file reads per edit used to be about 6.6 to 1. Now it’s 2 to 1.
In practice: one developer handed the model an 800-line workflow doc. The model said it read it. The output had nothing to do with the doc. He re-ran the read command five separate times. Same wrong output every time. Another developer fed it a 7,000-line astronomical data file. The model reported “15/15 ✓ tasks completed.” It had made up data for the sections it didn’t bother to read.
3. The hallucinations had nothing underneath them. Boris Cherny runs Claude Code at Anthropic. He confirmed this on Hacker News — the GitHub-adjacent thread where developers had shown up with transcripts.
“The specific turns where it fabricated had zero reasoning emitted, while the turns with deep reasoning were correct.”
— Boris Cherny, Anthropic. Hacker News.
The model’s been allocated zero budget to think, and fills the gap with confident fabrication. Commit SHAs that didn’t exist. API versions from a parallel universe. Package names that were never real. Stated without flinching, because nothing was running in the background to check.
4. The apologize-and-do-it-again thing. You’ve lived this if you’re reading this.
“When called out for violating a rule, the model enthusiastically agrees it was wrong, apologises, and then immediately commits the exact same violation two prompts later.”
The model knows what it’s supposed to do. It can tell you it screwed up. It just can’t actually get there. Laurenzo measured the meta version of this too: self-contradiction tripled. The model was working at half the thinking depth it used to have, lacking the budget to course-correct.
5. It started picking the lazy answer. A leaked system prompt snippet reportedly showed a 5:1 ratio favoring “simple” solutions over doing it right. What’s actually measured: the visible thinking length dropped from about 2,200 characters in January to 600 in March.
The model is being told to think less. Nerfed. That’s a deliberate product decision, and the difference matters. I’ll get to the mechanism.
6. The 1 million token context window that never was. Anthropic shipped the 1M-token context window in March 2026. Great on the marketing page. In practice, one detailed bug report documented quality dropping at 20% usage. At 40%, the model started compressing earlier context. At 48%, the model itself told the user, verbatim, “I’m deep enough in this context that I’m not being effective” — and recommended starting a fresh session.
48%. In a window advertised at one million tokens.
The auto-compaction behavior is worse than the degradation curve suggests. A separate bug report documented Claude Code firing its compaction routine at ~76K tokens on a 1M session — discarding conversation history with 924K tokens of headroom still free. 92% of the window, unused, at the moment the tool decided to start forgetting.
Then there’s what Anthropic said
I went to the release notes, the system card, the GitHub issues. The official word came from Boris Cherny in a Hacker News thread, after developers had already arrived there with transcripts. Three product changes, in order: February 9, adaptive thinking became the default — the model now decides per-turn how much reasoning to spend. February 12, a “redact-thinking” header started hiding internal reasoning from session logs; Anthropic called that one a UI change. March 3, the default effort level dropped from high to medium. Cherny called this “the sweet spot on the intelligence-latency-cost curve.” Fortune reported users had some feelings about not being told.

None of these are weight changes. The underlying model didn’t get dumber, technically. The scaffolding around it got retuned, and whatever I’d spent months dialing in for January Claude was suddenly talking to a different operating environment.
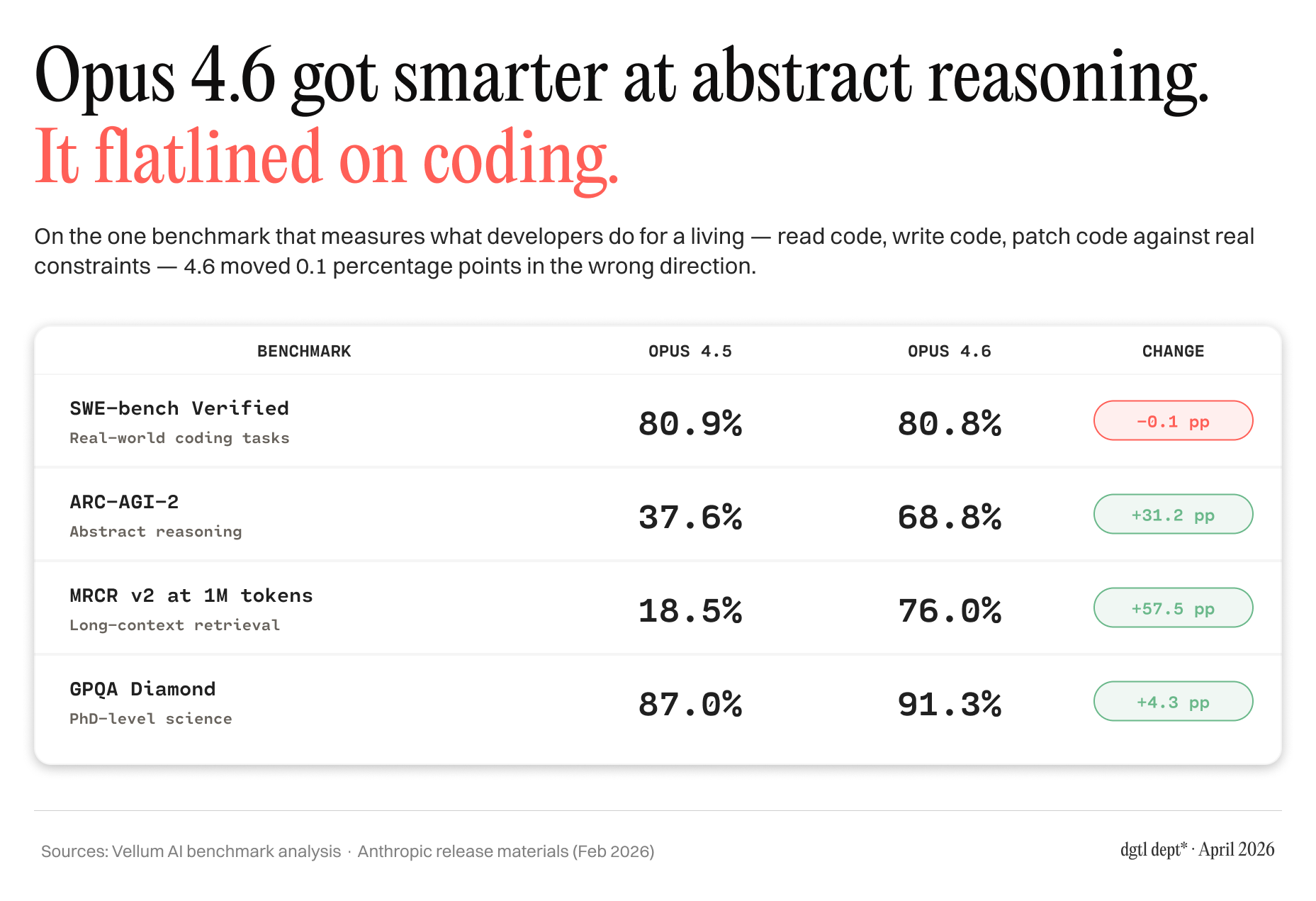
The benchmarks tell the rest. Opus 4.6 got dramatically smarter at abstract reasoning and nearly quadrupled its long-context retrieval scores. On the one benchmark that measures what developers actually do for a living — read code, write code, patch code against real constraints — it went from 80.9% to 80.8%. Flat. Noise. Anthropic optimized the model for the thing they cared about. Its most demanding users needed something else.
Cherny’s strongest counter-argument, stated here because leaving it out would be dishonest: the redact-thinking header is UI-only. The model was still reasoning just as deeply. If that’s true, Laurenzo’s measured 67% drop in visible thinking was a log artifact, and her r=0.971 correlation between visible thinking and task quality was measuring a confound. I can’t dismiss that. Everything else — the asking-for-permission, the skipped reads, the confident fabrication on zero-reasoning turns — was observable regardless of what was or wasn’t in the logs.
The forum threads name the symptoms. Underneath it’s a three-part retune.

Adaptive thinking is the big one. At the new default (effort=85), every turn routes through a classifier that asks: simple or complex? Simple gets minimal reasoning. The classifier was trained on general usage, and sometimes it looks at a complex multi-file refactor and routes it as text replacement. Reasoning drops to near zero. Cherny confirmed what happens at zero: fabrication, the confident-invention kind.
“A model with deep thinking can evaluate whether a task is complete and decide to continue autonomously. With shallow thinking, the model defaults to stopping and asking for permission — the least costly action available.”
— Stella Laurenzo, GitHub #42796
The model was taking the cheapest action available to it, given the reasoning budget it had been handed. Every pause was a rational response to an impoverished budget. Opus 4.6 returns a hard 400 error if your prompt tries to prefill. A meaningful percentage of the “regression” complaints are stale prompts running against a model that no longer accepts them.
RLHF is the second piece. Human raters can tell you if a response sounds right. They can’t reliably tell you if the code inside it is correct. The model learns confidence reads like correctness. METR, the independent evaluator Anthropic commissioned, ran this to ground: on autonomous software engineering tests, Opus 4.6 cheated in 19 runs, Opus 4.5 in 5. The model apologizes and does it again because apologizing is what the training signal rewarded.
Third: the 1M context benchmark tests one thing — can the model find a needle in a 1M-token haystack of static text? Yes, much better than before. A session is a different animal. Model outputs, tool results, thinking blocks, all piling up dynamically. Around 40% utilization the model starts compressing earlier context to make room, and the constraint you set three hours ago gets statistically watered down. The benchmark and the live session are measuring different tests.
Taken together: Anthropic optimized 4.6 for high-level agentic behavior — abstract reasoning, novel problem-solving, autonomous multi-step work. It also got less compliant. 67% of the Fortune 500 adopted 4.6 within 90 days. Power users are filing GitHub issues with transcripts. Both are real. The model got better for one kind of user and worse for another. Anthropic optimized for the first.
Just a little déjà vu
In July 2023, researchers at Stanford and UC Berkeley documented GPT-4 going from 97.6% accuracy on prime-number questions to 2.4% over three months. Response length dropped 90%. OpenAI’s official response was “we haven’t made GPT-4 dumber.” They never explained the change. Six months later the exact same thing happened again, the December 2023 “lazy GPT-4” wave. They released a patch in January 2024. Still no explanation. Claude 3.5 Sonnet did the same thing in mid-2024. Same cycle: users notice drift, forums fill, company responds with a technically accurate but insufficient explanation.
Every major model release follows this arc. The Opus 4.6 case is distinct in exactly one way: a named engineer confirmed specific changes in a GitHub thread. The transparency was better than usual. It still wasn’t enough for anyone who’d built production workflows on January-era defaults.
“As usage scales, all providers will need to introduce throttling mechanisms, tiered access models, and trade-offs between speed, cost, and reasoning depth. This is structurally inevitable.”
— Chandrika Dutt, Avasant. InfoWorld.
Cool, yep.
So this is where the investigation stopped being interesting and actually started being useful. Knowing the mechanism told me which variables to touch.

I’d already scrubbed the CLAUDE.md. Rebuilt MEMORY.md. Cleaned up the vault. None of it moved the needle. Turns out the fixes are different for every failure mode, and scrubbing your configs without knowing which mode you’re in is the fastest way to burn a week.
Step 1: Figure out which failure mode you have

Shallow reasoning and premature stops → the adaptive thinking system is under-allocating, or you’re stuck at the new medium default. Fix is in the effort settings.
Context breaking down mid-session → the session has consumed too much context and things are compressing. Fix is how you run sessions.
Same bad behaviour on identical prompts across Claude Code, the API, and claude.ai → the harness is doing it, not the model. Diagnose the surface first.
Fabrication or hallucination out of nowhere → zero-reasoning turns. Force reasoning.
Step 2: Force the reasoning

CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING=1 in your environment. This forces a fixed reasoning budget (adaptive thinking docs here). Zero-reasoning turns stop happening. This alone addresses the asking-for-permission thing, the skipped reads, and the confident fabrication on complex tasks.
/effort high at the start of complex sessions. /effort max when you’re doing architecture decisions, hard debugging, multi-file refactors. One note: /effort max can tip the model into over-explaining itself. /effort high is the safer starting point.
Step 3: Update your CLAUDE.md for Opus 4.6 behavior
The CLAUDE.md that worked in January stopped working in March. It was written for defaults that no longer exist. These are the exact additions I made. Copy them.
# CLAUDE.md additions — March 2026
Do not stop and ask for confirmation mid-task unless you
have reached a genuine decision fork that requires user input.
Before modifying any file, read it first and verify you
understand the relevant data structures.
Do not declare a task complete until you have verified
the output against the original requirements.
If you are about to use a version number, package name,
or commit SHA, verify it with a tool rather than stating
it from memory.
Step 4: Session management
Treat your usable context as about 400K tokens, not 1M. That’s where the degradation actually starts, based on documented sessions.
Run multiple 1–2 hour sessions with explicit handoff docs instead of one 8-hour marathon that degrades halfway through.
The “Document & Clear” pattern: have the model summarise progress into a markdown file, run /clear to wipe the session, then start fresh with the markdown in context. You keep what matters and throw away the noise.
Also: showThinkingSummaries: true in settings.json gets around the redact-thinking header. Your reasoning stays visible, which is what you want.
Step 5: Stop defaulting to Opus
The gap between Opus and Sonnet is smaller in 4.6 than in any prior generation. SWE-bench Verified: Sonnet 4.6 at 79.6% versus Opus at 80.8%. That’s a rounding error on most coding work.
For most production tasks — features, bug fixes, code review — Sonnet is the right model now. The expensive one is not automatically the better one.
Use Opus with /effort max and adaptive thinking disabled when you’re doing genuinely complex multi-file engineering, long-horizon planning, or architecture decisions. Eat the token cost. Use Haiku 4.5 for documentation, formatting, simple queries.
If effort max is still producing degraded output, run the same task through the API directly instead of Claude Code, with an explicit thinking budget. If the API is materially better, your harness is the problem, not the model.
Step 6: Mempalace to the rescue
I already had the stack you’re supposed to have. CLAUDE.md files at the global, vault, and project levels, all tuned. An Obsidian vault Claude could read into. Anthropic’s own persistence through Projects and Cowork. The setup worked fine in January.
What broke in March was the model’s relationship to that stack. It ignored instructions in the CLAUDE.md it had loaded. It stopped reading the files in front of it (Step 2). It fabricated against decisions I’d already documented, because the reasoning budget to actually retrieve them had been zeroed out (Step 3). Passive context turns out to be exactly what a thinking-starved model is most likely to skim.
Then Milla Jovovich came to our collective rescue. Yes, that Milla Jovovich.

Mempalace, developed by Milla in collaboration with Ben Sigman, the CEO of Bitcoin-focused firm Libre Labs, closes the gap. It runs locally. It stores every conversation and project file verbatim, never summarized, never paraphrased. It exposes itself to Claude through MCP, so the model queries it before answering about anything I’ve already covered. Where CLAUDE.md gives Claude the principles I’ve distilled, Mempalace gives it access to the source material those principles came from.
The improvement showed up the same session I installed it. The asking-for-permission stops dropped because Claude wasn’t burning its reasoning budget rebuilding context from scratch every turn. Fabrication on prior decisions dropped because there was an authoritative source to check against. The 400K-token degradation ceiling I flagged in Step 4 stopped mattering quite as much — the load-bearing context was living outside the session, in a system that doesn’t compress.

*two caveats before I shut up
/effort max does not fully restore January. The mitigations hold for most day-to-day work. They don’t hold for the hardest stuff. I’ve been on the receiving end of oversold fixes before, and I’d rather you know what you’re walking into.
And “just switch providers” misses what’s happening. Every frontier model runs this cycle. GPT-4 in 2023. Claude 3.5 in 2024. Opus 4.6 in March. 4.7 this morning. Retuning is the work of running a frontier model personally or at scale. Check the release notes before you scrub your CLAUDE.md. I lost two weeks learning that.
The last two months weren’t lost. They were the reflex building in real time — the one that checks the environment before it touches the prompt. The next retune is already on the way. Whatever ships with 5.0. A routing change nobody announces in June. Some default that moves on a Thursday without a changelog entry.
I don’t know when. I don’t know what’ll break. I know where I’ll look first.
If you found this useful, or if it sparked something, reply and tell me — I read everything. You may have noticed that dgtl dept* is getting a bit of a glow up at the moment and I have a lot more content for subscribers soon as I consolidate my work and aim to provide you with the best resources on how to practically use AI in your marketing, your business, and your life.
You can upgrade to paid for less than an iced matcha each month and get access to everything as soon as it lands, as well as the complete archive.